SELECT문
SELECT <attribure list>
FROM <table list>
WHERE <condition>;
작동 방식:
대상 테이블을 찾고 where 조건 에 맞는 튜플들을 찾은 후 원하는 attribute들만 추출한다.
FROM -> WHERE -> SELECT 순으로 작동
- WHERE 절을 생략하는 경우, FROM 절의 테이블들을 카티션 프로덕트한 결과를 보여준다.
- 테이블의 모든 attributes을 검색하고 싶다면 * 을 사용하면 된다.
- SQL에서 table은 꼭 집합일 필요 없음. 따라서 중복을 허용한다(중복을 자동으로 제거하지 않는다). 왜?
- 중복 제거 연산이 비쌈. sorting 하는 연산은 비싼 연산이다.
- 유저가 중복을 원할 경우도 있을 수 있다.
- 집단 함수에서 중복을 제거해 버리면 결과가 달라져버린다. -> 유저가 중복을 선택할 수 있도록 한다. (ALL, DISTINCT 키워드)
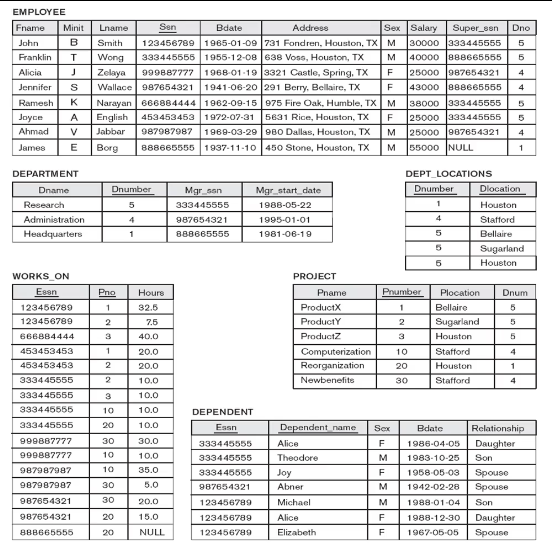
문제 1) 'John B.Smith' 직원의 생일과 주소를 검색라
SELECT Bdate, Address
FROM EMPLOYEE
WHERE Fname='John' AND Minit='B' AND Lname='Smith';
문제 2) 성별이 남자이거나 급여가 35000 이상인 직원의 이름과 급여를 검색해라
SELECT Lname, Salary
FROM EMPLOYEE
WHERE Sex='M' OR Salary > 35000;문제 3)'Research' 부서에 일하는 직원의 이름과 주소를 검색해라.
SELECT Fname, Lname, Address
FROM EMPLOYEE, DEPARTMENT
WHERE Dname = 'Research' AND DEPARTMENT.Dnumber = EMPLOYEE.Dno
문제4) Stafford에 위치하는 모든 프로젝트의 project number, 제어하는 department number, department manager의 last name, 주소, 생일을 검색하라
SELECT Pnumber, Dnum, Lname, Address, Bdate
FROM PROJECT, DEPARTMENT, EMPLOYEE
WHERE Dnum=Dnumber AND Mgr_ssn=Ssn AND Plocation='Stafford';
문제 5) 직원의 이름과 그 직원의 직속 상사의 이름을 검색해라
SELECT E.Fname, E.Lname, S.Fname, S.Lname
FROM EMPLOLYEE AS E, EMPLOYEE AS S
WHERE E.Supper_ssn = S.Ssn;-> self-join 쿼리라 부른다. , AS는 생략 가능하다. 한번 이름을 바꾸면 그 이름은 그 쿼리에서 다시 사용할 수 없다.
집합 연산
UNION, EXCEPT, INTERSECT
UNION -> {a, b} ∪ {b, c} = {a, b, c}
UNION ALL, EXCEPT ALL, INTERSECT ALL
UNION ALL -> {a, b} ∪ {b, c} = {a, b, b, c}
* 집합을 하기 위한 양쪽 테이블의 컬럼 수 같아야 하고, 같은 도메인을 가져야 한다.(구조가 동일해야 한다) -> union compatible
* OR 연산과 UNION 연산은 서로 바꿔 줄 수 있다.

Lname이 'Wong'인 직원이 직원으로 또는 부서의 매니저로 참여한 프로젝트의 번호를 검색하라
(SELECT DISTINCT Pno
FROM WORKS_ON, EMPLOYEE
WHERE Essn=Ssn AND Lnam='Wong')
UNION
(SELECT DISTINCT Pnumber
FROM PROJECT, DEPARTMENT, EMPLOYEE
WHERE Dnum=Dnumber AND Mgr_ssn=Ssn AND Lnam='Wong');
패턴 매칭 (LIKE)
% : 여러 글자
WHERE address LIKE '%Houston,TX%';
_ : 한 글자
WHERE Bdate LIKE '__5_______';
* 검색 결과에 수식을 줄 수 있다. -> 실제 데이터를 바꾸는 것은 아님
* 해딩이 나오지 않기 때문에 이름을 줘야한다.
* 두 컬럼에 내용을 합치는 것도 가능 '||'
ex) SELECT Fname, Lname, 1.1*Salary As INCREAD_SAL
BETWEEN AND
SELECT *
FROM EMPLOYEE
WHERE (Salary BETWEEN 30000 AND 40000 ) AND Dno = 5;
ORDER BY
검색 결과의 순서를 부여할 수 있다.
ORDER BY 절에는 반드시 SELECT 절에 있는 필드들만 가능하다.
ASC : 오름차순 - default
DESC: 내림차순
ex) ORDERB BY name DESC, Lname ASC, Fname ASC
SELECT Fname, Lname, Dno
FROM EMPLOYEE
ORDER BY Dno, Lname, Fname;
INSERT문
INSERT INTO EMPLOYEE
VALUES ('Richard', 'K', "Marini', '65398653', '1962-12-30', '98 Oak Forest', Katy, TX', 'M', 37000, '987654321', 4)INTERT INTO EMPLOYEE(Fname, Lname, Dno, Ssn)
VALUES ('Richard', 'Marini', 4, '654298653');특정 필드 데이터만 삽입하는 것도 가능 -> 나머지 필드는 NULL로 셋팅된다.
* VALUES 절 대신에 SQL문이 들어갈 수 있다.
INSERT INTO WORKS_ON_INFO(Emp_name, Proj_name, Hours_per_week)
SELECT E.Lname, P.Panem, W.Hours
FROM PROJECT P, WORKS_ON W, EMPLOYEE E
WHERE P.Pnjmber=W>Pno AND W.Essn=E.ssn;
DELETE 문
DELETE FROM EMPLOYEE
WHERE Lname='Brown';* 연쇄 삭제가 일어날 수 있어 주의해야한다. CASCADE 옵션 주의
UPDATE 문
UPDATE PROJECT
SET Plocation='Bellaire', Dnum=5
WHERE Pnumber=10;Pnumber가 10인 튜플들을 찾아서 Plocation과 Dnum 값을 바꿔라
'CS > 데이터베이스' 카테고리의 다른 글
| [데이터베이스 기초] 복잡한 질의 정리 (WITH, CASE, Recursive Queries) (1) | 2023.10.15 |
|---|---|
| [데이터베이스 기초] SQL의 집단함수와 GROUP BY 절, HAVING 절 정리 (0) | 2023.10.15 |
| [데이터베이스 기초] SQL 중첩 쿼리와 조인 쿼리 정리 (1) | 2023.10.15 |
| [데이터베이스 기초] SQL DDL문 정리 (CREATE, DROP, ALTER) (1) | 2023.10.13 |
| [데이터베이스 기초] Relational Data Model 과 Constraints (1) | 2023.10.13 |

