Relational Algebra
릴레이션을 조작하기 위한 연산들의 집합으로 검색 요구를 명세하는데 주로 사용, 질의 결과는 릴레이션 형태로 표현한다.
Relational Operations
- SELECT(σ)와 PROJECT(𝛑) 연산
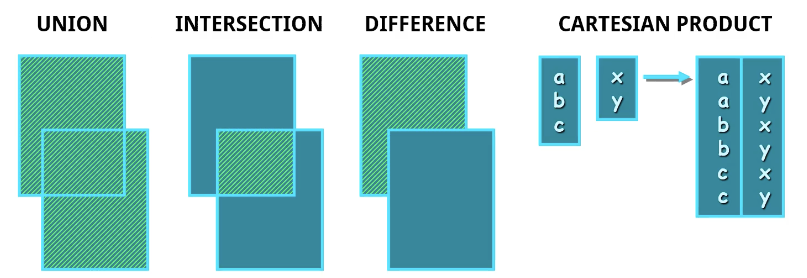
- UNION (⋃), INTERSECTION (⋂), DIFFERENCE (-), CARTESIAN PRODUCT (x)
- JOIN(⋈) 연산
- DIVISION, OUTER JOIN, AGGREGATE FUNCTIONS
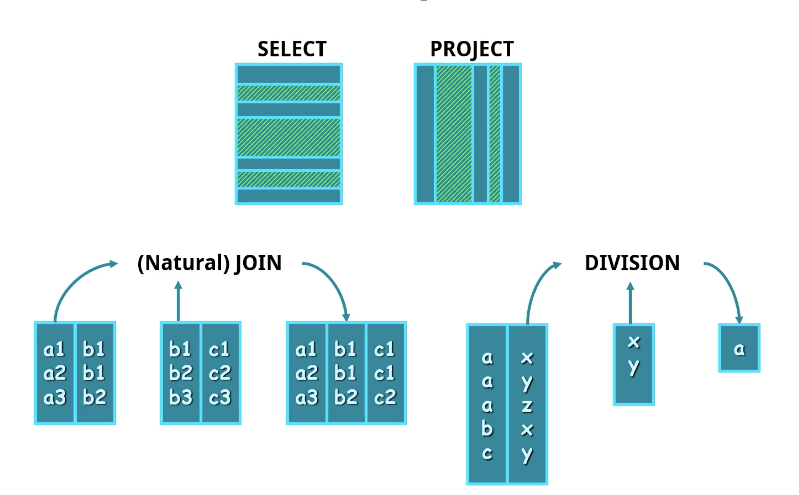
SELECT 연산 (σ)
조건에 만족하는 튜플들의 부분 집합을 선택하는 연산
조건에는{=, <, <=, >=, !=} 연산들이 사용되고, AND, OR, NOT 을 통해 조건들이 연결될 수 있다.

- Selectivity(선택률) : |σ(R)| / |R| -> SELECT 결과 릴레이션의 튜플 수 / 전체 튜플 수
- 선택률은 DBMS가 질의 처리를 할 때 여러가지 선택 조건 중 어떤 조건을 먼저 처리할 지 선택하는데 사용
- SELECT 연산은 교환법칙이 성립한다.
- 여러개의 SELECT 연산은 조건을 AND로 연결한 결과와 동일 하다.
PROJECT 연산 (𝛑)
주어진 릴레이션에서 명세된 애트리뷰트만 뽑아내는 연산이다.
* 프로젝트 연산의 결과는 릴레이션으로 중복을 제거한다.
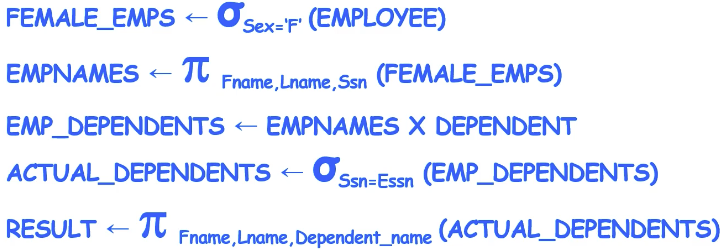
Relational Algebra (관계대수식)
5번 부서에서 일하는 직원의 이름과 급여를 검색하라!

두개의 연산으로 나눠서 표현도 가능하다.

* 검색 결과에 이름을 다시 주는 것도 가능하다. ex) R(First_name, Last_name, Salary)
RENAME 연산 (ρ)

릴레이션의 이름과 속성 전부 변경 or 릴레이션 이름만 변경 or 릴레이션 속성만 변경 가능하다.
집합 연산
Union compatibility (결합 가능) 해야한다. (합집합, 교집합, 차집합)
-> 1) 애트리뷰트 수가 같아야 한다. 2) 애트리뷰트 도메인이 서로 같아야 한다.
편의 상 집합 연산 결과 릴레이션은 앞의 릴레이션의 이름을 따른다.
CARTESIAN PRODUCT

- Q의 차수 = R 차수 + S 차수, Q의 튜플 수 (Cardinarity) = R의 튜플 수 * S의 튜플 수
- Cross product 또는 Cross join 연산이라고 부르기도 함
- 자체로는 별 의미가 없지만 SELECT 연산과 함께 사용하면 JOIN 연산과 같은 효과를 낼 수 있다.
여성 직원의 부양 가족 이름들을 검색해라!
JOIN 연산
CARTESIAN PRODUCT 와 SELECT를 한 결과와 동일한 결과가 나온다.

THETA JOIN : 조건에 {=, <, <=, >=, !=} 연산이 사용되는 경우
EQUIJOIN : THETA JOIN 중 {=} 연산을 사용하는 경우
NATURAL JOIN (*)

EQUIJOIN은 같은 attribute 끼리 조인하기 때문에 결과에 동일한 attribute가 중복되서 나오는 문제가 있다.
NATURAL JOIN은 같은 이름을 갖는 attribute끼리 모두 조인하고 결과에서 중복된 attribute는 한번만 나온다.
단, 이름이 같아야 하기 때문에 이름이 다르다면 이름을 동일할게 맞춰줘야 한다. 특별이 조인 컨디션이 필요없음
PROJECT와 그 PROJECT를 관리하는 DEPARTMENT를 조인해라

Join selectivity = |R ⋈ S| / |R| *|S|
R과 S의 조인 후 튜플 수 / R과 S의 CARTESIAN PRODUCT 후 튜플 수
-> 질의 처리할 때 참조하는 중요한 정보임
Relationally Complete
관계대수 8가지 연산(집합 연산 4가지 + 관계 연산 4가지) 을 SELECT, PROJECT, UNION, SET DIFFERENCE, CARTESIAN PRODUCT 5가지 연산의 시퀀스로 표현할 수 있다. 이 다섯가지 연산을 관계대수 연산의 COMPLETE SET이라고 한다.
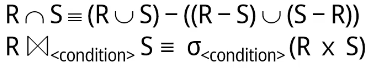
어떤 언어가 {σ, 𝛑, ⋃, -, x} 이 다섯가지 연산을 제공한다면 relationally complete라고 한다.
DIVISION 연산
ex) C1, C2, C3 코스를 모두 수강하고 있는 학생을 찾고 싶을 때

'John Smith'가 일하고 있는 프로젝트에 참여한 모든 직원의 이름을 검색하라!


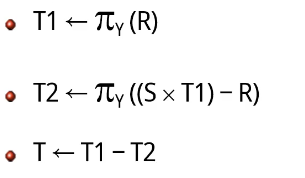
위의 연산으로 DIVISION 연산을 대신할 수 있다.
Query Tree
관계대수식을 Tree 형태로 표현한 자료구조
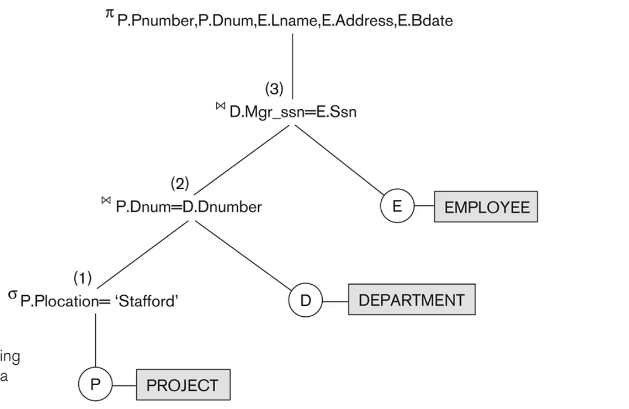
ex) Stafford에 위치하는 모든 프로젝트에 대해서 프로젝트 번호, 관리하는 부서 번호, 부서 매니저의 이름, 주소 생일을 검색하라
관계대수식

Query Tree
추가적인 관계 연산
OUTER JOIN

OUTER UNION
union compatible 하지 않은 두 릴레이션의 튜플들을 합집합하는 연산이다.

SEMIJOIN

릴레이션 R의 튜플 중 S와 조인에 참가하는 튜플들만 뽑아내는 연산이다.
* 교환법칙을 성립하지 않는다.
관계 해석
relation algebra 와 다르게 비절차적 언어이다.
검색 요구를 선언적으로 표시하고 쿼리를 평가하는 방법에 대해서는 기술하지 않는다.
Tuple relational calculus (튜플 해석)와 Domain relational calculus (도메인 해석) 가 있다.
'John B.Smith' 라는 직원의 생일과 주소를 검색하라!
SQL
SELECT Bdate, Address
FROM EMPLOYEE
WHERE Fname='John' AND Minit='B' AND Lname='Smith';
관계대수

관계해석

'CS > 데이터베이스' 카테고리의 다른 글
| [데이터베이스 기초] 정규화 정리 (1) | 2023.10.17 |
|---|---|
| [데이터베이스 기초] Entity-Relationship (ER) Model 정리 (1) | 2023.10.16 |
| [데이터베이스 기초] SQL의 VIEW 정리 (0) | 2023.10.16 |
| [데이터베이스 기초] SQL CREATE ASSERTION 과 TRIGGER 정리 (1) | 2023.10.15 |
| [데이터베이스 기초] 복잡한 질의 정리 (WITH, CASE, Recursive Queries) (1) | 2023.10.15 |


