좋은 릴레이션 스키마란?
- 논리적인 수준에서는 릴레이션이 데이터 의미를 얼마나 잘 표현하고 있는 지,
- 구현 수준에서는 베이스 릴레이션의 스키마가 어떻게 구성되어 있는 지가 판단 기준이 된다.
릴레이션 스키마의 품질 측정 기준
- 애트리뷰트의 의미를 스키마가 명확하게 표현하고 있는 가
- 튜플의 중복값을 얼마나 감소시킬 수 있는 가
- 튜플의 NULL 값을 얼마나 줄일 수 있는 가
- 불필요한 튜플 생성 가능성을 허용하면 안 된다.
릴레이션 품질을 위한 가이드라인
1) 하나의 엔티티 또는 릴레이션 타입 에는 하나의 릴레이션 스키마를 설계해라!
- 하나의 릴레이션 스키마에 여러개의 개체나 관계 타입을 섞어 놓아서는 안된다.
- 관계 스키마를 설계할 때 의미를 쉽게 설명할 수 있어야 한다.
- 문제점 : 중복값이 많이 생긴다.
2) insertion, deletion, or modification anomalies 가 생기지 않도록 해야한다.
- 만약 어쩔 수 없다면 그 상황을 명확히 기술해서 데이터를 업데이트하는 프로그램이 정확히 작동하도록 해야한다.
- 하지만 특정 질의 성능을 위해서 위반될 수 있음
- ex) 직원과 부서의 정보를 함께 자주 검색하면 성능을 위해 합쳐서 유지하는 것이 효율적일 수 있다.
Update Anomalies 문제
데이터 중복으로 발생한다 -> 한 테이블에 여러 정보가 섞여서
EMP_DEPT(Ename, Ssn, Bdate, Address, Dnumber, Dname, Dmgr_ssn)
Insertion anomalies
EMP_DEPT에 부서 정보 (null, null, null, null, 6, Security, null) 데이터를 삽입하려 하면 어떻게 될까?
기본키값이 null로 개체 무결성을 위반하여 삽입이 안된다. 부서 정보를 삽입하려는데 관련없는 직원 정보 때문에 삽입이 안된다.
서로 다른 정보가 한 테이블에 섞여있어 생기는 문제이다.
Deletion anomalies
특정 직원을 삭제 하려할 때 만약 그 직원이 어떤 부서의 마지막 직원이라면? 직원을 삭제했더니 부서도 삭제되어 버리는 문제가 생긴다.
관련없는 정보도 함께 삭제되는 연쇄삭제 현상이 일어난다.
Modification anomalies
Dmgr_ssn을 수정할 때 모든 튜플의 특정 값을 모두 수정해야 한다. 만약 하나라도 빠지면 데이터 불일치 문제가 발생한다.
3) 베이스 릴레이션에 NULL 값이 자주 들어가도록 하지 마라
- 만약 NULL을 피할 수 없다면 특정한 예외 상황에만 NULL이 적용될 수 있도록 릴레이션을 구성해라
- NULL 이 빈번하면 공간 낭비, 애트리뷰트 의미나, 조인 연산 문제, 집단 함수 수행시 해석상의 모호함, NULL 자체도 여러 해석으로 인한 모호성 문제 등이 있다.
4)릴레이션 스키마를 설계할 때 조인시 반드시 PK-FK 쌍의 동등조건으로 수행되도록 해라
- 잉여 튜플이 발생하지 않는 것을 보장할 수 있다.
Functional Dependency (함수적 종속성)
A functional dependency : X -> Y

임의의 두 튜플에서 X 애트리뷰트 값이 결정되면 Y 애트리뷰트 값도 결정된다.
X: 결정자, Y: 종속자라 부른다. ex) Ssn -> Ename , Pnumber -> {Pname, Plocation}, {Ssn, Pnumber} -> Hours
- 스키마만 보고 함수적 종속성이 있다 없다를 판단할 수 없다.
- 함수적 종속성은 속성에 의미에 관련된 성질이다.
- 모든 데이터가 따라야 하는 조건이다.
Trivial Dependency : {Ssn, Pnumber} -> Pnumber 처럼 종속자가 결정자에 포함되는 경우 (당연함 결과)
기본키를 기반으로한 정규형
- 정규형이란 관계형 데이터베이스의 스키마가 정해진 규칙을 얼마나 따르는지 측정할 수 있는 form이다.
- 정규화 과정은 테스트를 통해서 릴레이션이 normal form에 만족하는 지 확인하는 과정이다.
- 주어진 릴레이션을 기본키와 함수적 종속성에 기반하여 중복성을 줄이고, insertion, deletion, update anomalies를 최소화 한다.
- 만족되지 않는 릴레이션 스키마를 더 작은 만족하는 릴레이션 스키마로 분해한다.
분해하는 정규화 과정에서 만족해야 하는 2가지 성질
- Lossless join property : 분해된 릴레이션을 원래 릴레이션으로 만들 때 잉여 튜플이 생겨서는 안된다.
- Dependency preservation property (종속성 보존 법칙) : 원래 릴레이션의 함수 종속성은 분해되어서도 존재해야 한다.
* Denormalization : 조인 비용이 비싸기 때문에 다시 하나로 합치는 과정 (역정규화)
1st normal form (제 1 정규형)
애트리뷰트를 구성하는 도메인이 atomic 해야 한다. (single value를 갖어야 한다.)
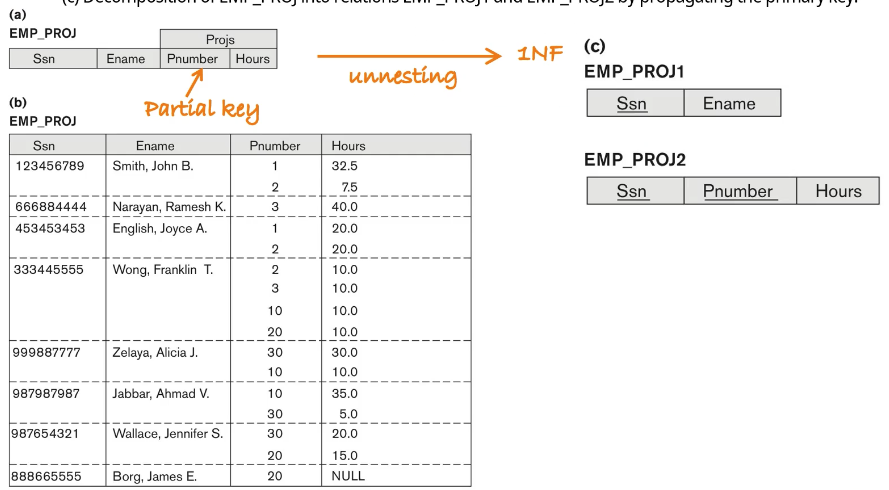
Non-1NF 를 1NF 로 바꾸는 방법
- nonatomic attribute를 별도의 릴레이션으로 분리하는 방법, 원래 릴레이션의 기본키를 같이 붙여서 내보낸다.
- set value를 여러개의 튜플로 분리한다. (중복이 많이 생기는 문제가 생긴다)
- 여러개의 애트리뷰트로 나눈다. ex) {Dname, Dnumber, Dmgr_ssn, Dlocation1, Dlocation2, Dlocation3 ... } (null이 많이 생기는 문제가 생긴다.)
Full Functional Dependency (완전 함수 종속)
WORKS_ON(Ssn, Pnumber, Hours) , {Ssn, Pnumber} -> Hours 일때 Hours를 결정하기 위해서는 Ssn, Pnumber가 모두 필요하다 이런 경우를 완전 함수 종속(FFD)이라 하고
EMPLOYEE(Ssn, Ename, Bdate, ...) , {Ssn, Ename} -> Bdate 일때 Ssn만 갖고도 Bdate를 결정할 수 있다. Ename이 없어도 된다. 이런 경우를 부분 함수 종속(PD)이라 한다.
2nd normal form (제 2 정규형)
키에 속하지 않는 모든 애트리뷰트가 기본키의 완전 함수 종속이어야 한다.

Transitive Dependency (이행적 종속성)
X -> Z AND Z -> Y 이면 X -> Y 인 성질이다.

TD : Ssn -> Dname , Ssn -> Dmgr_ssn
3rd normal form (제 3 정규형)
제 2 정규형을 만족하면서 어떤 nonprime 애트리뷰트도 기본키에 이행적 종속성을 가져서는 안된다.
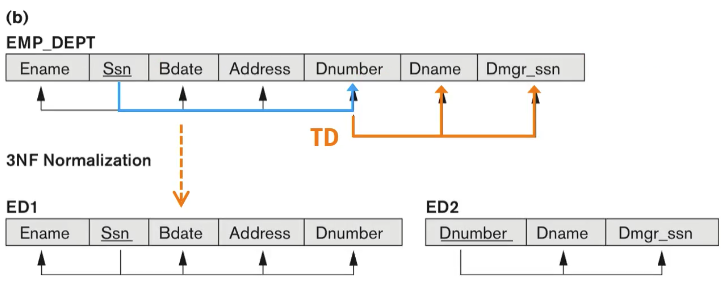
제 2, 3 정규형에 대한 좀 더 일반적인 정의
지금까지는 기본키와 다른 애트리뷰트 사이의 관계 기반으로 정의 했다면 좀 더 일반적인 정의에서는 기본키를 모든 후보키로 좀 더 확장해서 정의한다.
General 2NF :모든 nonprime 애트리뷰트가 모든 후보키에 완전 함수 종속이어야 한다.
General 3NF : FD X -> A, X가 슈퍼키 이거나, A가 prime 애트리뷰트이면 된다.
모든 nonprime 애트리뷰트가 모든 키의 완전 함수 종속이면서 모든 키에 이행적으로 종속이 되어서는 안된다.
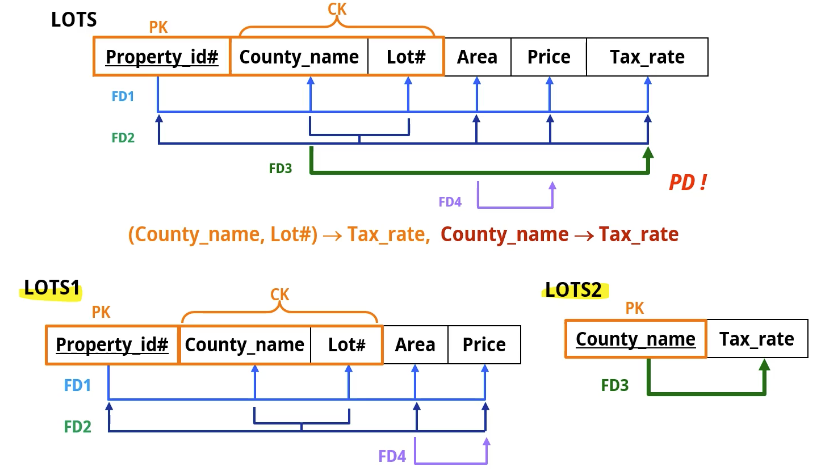
FD3는 County_name 혼자 Price를 결정하고 있어 문제가 된다. -> 제 1 정규형임.

Boyce-Codd normal form (BCNF)
제 3 정규형에서 나온 2가지 조건 중 종속성 X->A가 존재할 때 A가 prime 애트리뷰트여야 한다는 조건이 빠진 정의이다.
즉, 모든 결정자가 X의 슈퍼키여야 성립한다. 키가 아닌 결정자가 존재하면 안된다.
다른말로 Strong 3rd normal form이라 한다.
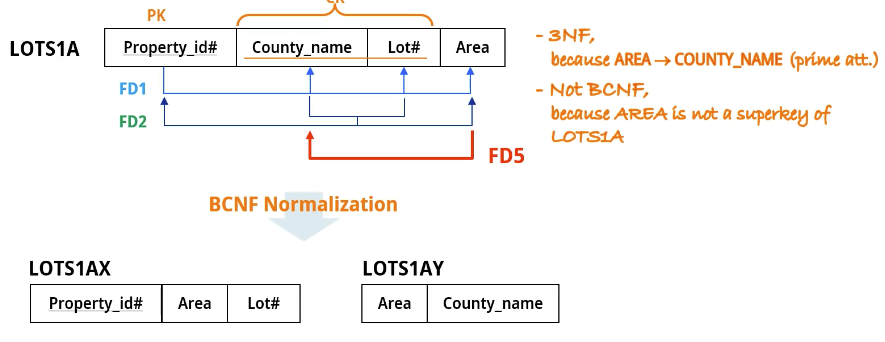
FD5 : Arear -> County_name
County_name이 prime 애트리뷰트로 3NF는 만족하지만 Area 가 superkey가 아니라 BCNF는 만족하지 못 한다.
* X->A 일때 X가 슈퍼키가 아니고 A가 prime 애트리뷰트면 3NF는 만족하지만 BCNF는 만족하지 않는다.
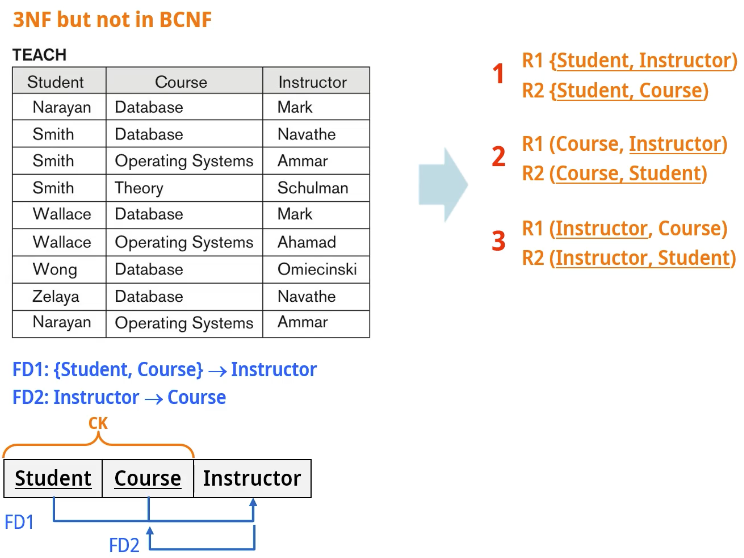
1, 2, 3 모두 FD1의 종속성을 표현하지 못하기 때문에 바람직하지 못하지만 그나마 3번이 가능성있다.
1, 2 은 PK-FK 쌍으로 조인하지 않았다. -> 잉여 튜플이 발생할 수 있음
Multivaluerd Dependency (다치 종속)
결정자 하나에 종속자 집합이 대응되는 경우이다.
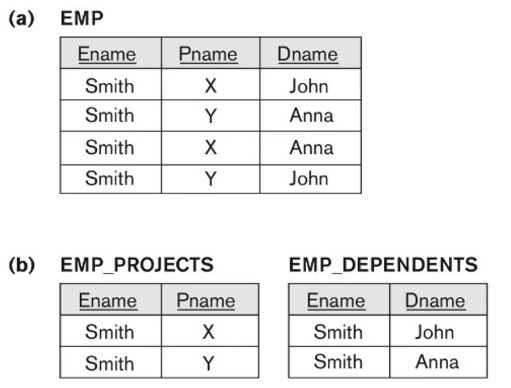
Smith에 의해 X, Y 가 결정되고, John, Anna가 결정된다.

Multivaluerd Dependency (다치 종속) 문제점
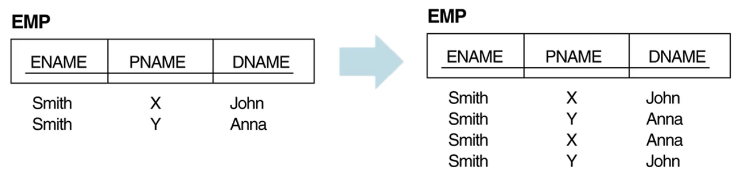
EMP를 (ENAME, PNAME) , (ENAME, DNAME) 로 분리했다가 다시 합치면 오른쪽 처럼 잉여 튜플들이 생긴다.
데이터 중복으로 인해 튜플을 지울때도 여러개를 지워야 하는 문제가 생긴다. 그래서 제 4 정규형을 정의한다.
제 4 정규형
MVD가 존재하지 않는 경우를 말한다. 테이블에 다치 종속이 존재하지 않으면 제 4 정규형을 만족한다.

Join Dependency
지금까지는 릴레이션을 2개로 나눠 해결했다면 Join Dependency는 여러개로 나눠야 해결된다.
그래야 잉여 튜플이 발생하지 않을 경우를 말한다.
즉, n개의 서브 릴레이션으로 나눠야 원래 릴레이션을 만들 수 있을 때 Join Dependency라 한다.
MVD 는 Join Dependency의 특수한 경우 이다. MVD의 특수한 경우가 Functional Dependency 이다.
제 5 정규형
프로젝션과 조인할 때 걸리는 정규형으로 Projection-Join Normal Form (PJNF) 라고도 한다.
n개로 프로젝션된 서브 릴레이션들이 다시 원래 릴레이션을 만들기 위해 조인할 때 각각의 모든 서브 릴레이션들이 모두 원래 릴레이션의 슈퍼키로 구성되었을 때 만족한다.

SUPPLY 는 프로젝션하면 R1, R2, R3 3개로 프로젝션 할 수 있다. 3개 모두 조인해야 원래 릴레이션을 만들 수 있다.
SUPPLY는 제 5 정규형에 만족하지 못 한다. 프로젝션 했을 때 R1, R2, R3 모두 SUPPLY의 슈퍼키로 구성되지 않았기 때문이다. (키의 일부만 있음)
제 5 정규형에 만족시키기 위해 실제 R1, R2, R3 릴레이션으로 나눠줘야 한다. (차수가 2인 경우는 무조건 제 5 정규형에 만족한다)
실제로는 제 4, 5 정규형은 드문 케이스로 제 3 정규형이 BCNF인지 까지만 확인한다.
'CS > 데이터베이스' 카테고리의 다른 글
| [데이터베이스 기초] Entity-Relationship (ER) Model 정리 (1) | 2023.10.16 |
|---|---|
| [데이터베이스 기초] 관계대수식 정리 (1) | 2023.10.16 |
| [데이터베이스 기초] SQL의 VIEW 정리 (0) | 2023.10.16 |
| [데이터베이스 기초] SQL CREATE ASSERTION 과 TRIGGER 정리 (1) | 2023.10.15 |
| [데이터베이스 기초] 복잡한 질의 정리 (WITH, CASE, Recursive Queries) (1) | 2023.10.15 |


